Poggio Labs
Managing and tracking customer relationships and sales processes across fragmented workflows and disconnected data is challenging for Sales teams. Traditional CRMs don't evolve with businesses and require Sales teams to conform.
Poggio is a highly customizable and flexible sales CRM that evolves with businesses, allowing teams to surface customer data in ways that fit their unique workflows. I helped companies make the most of their data, focusing on how data is configured and how its surfaced in the CRM's core views. Here are a few things I worked on.
Extending the integration setup and configuration

Increasing speed to value by enabling our users to self-serve activation
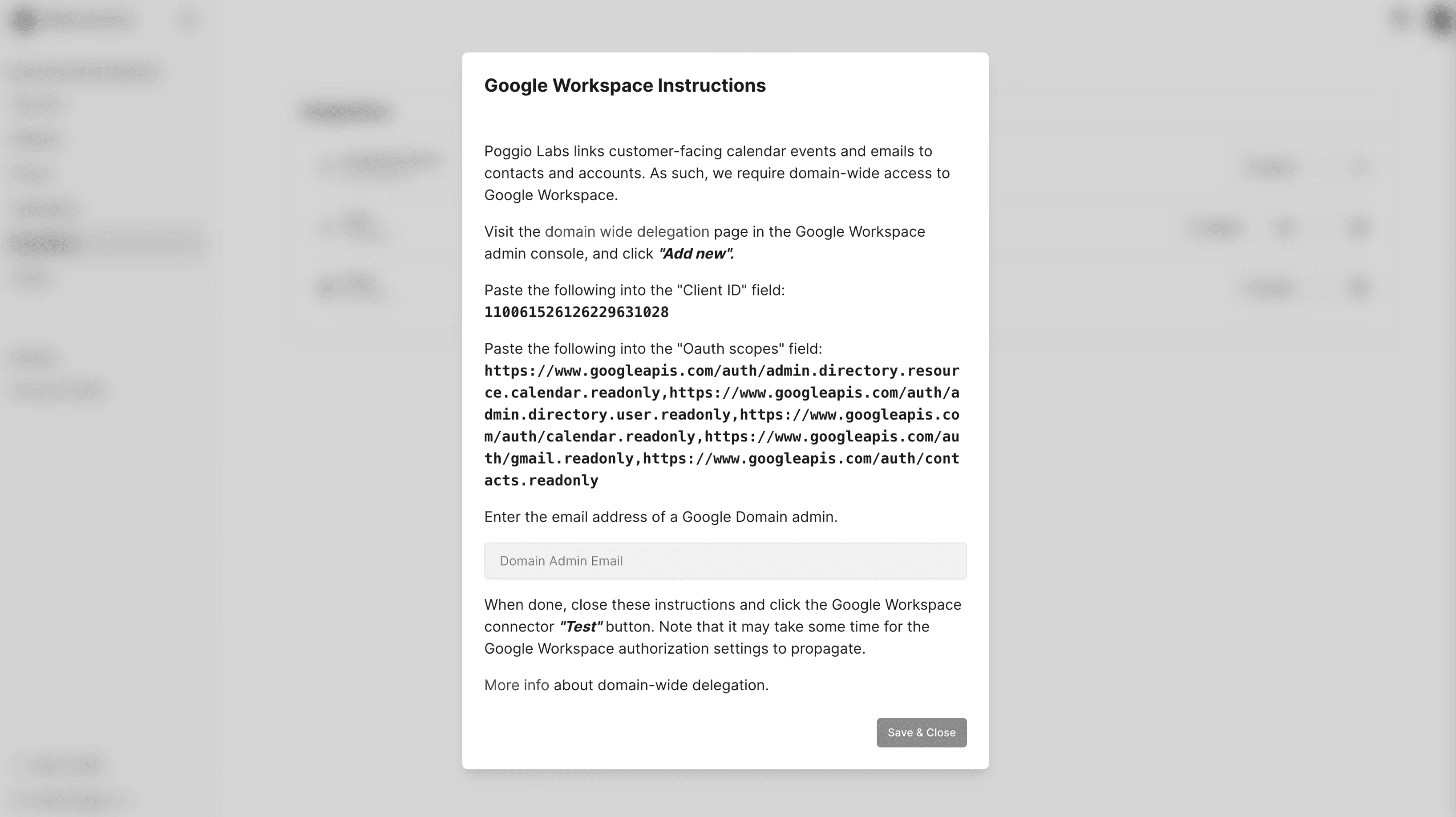
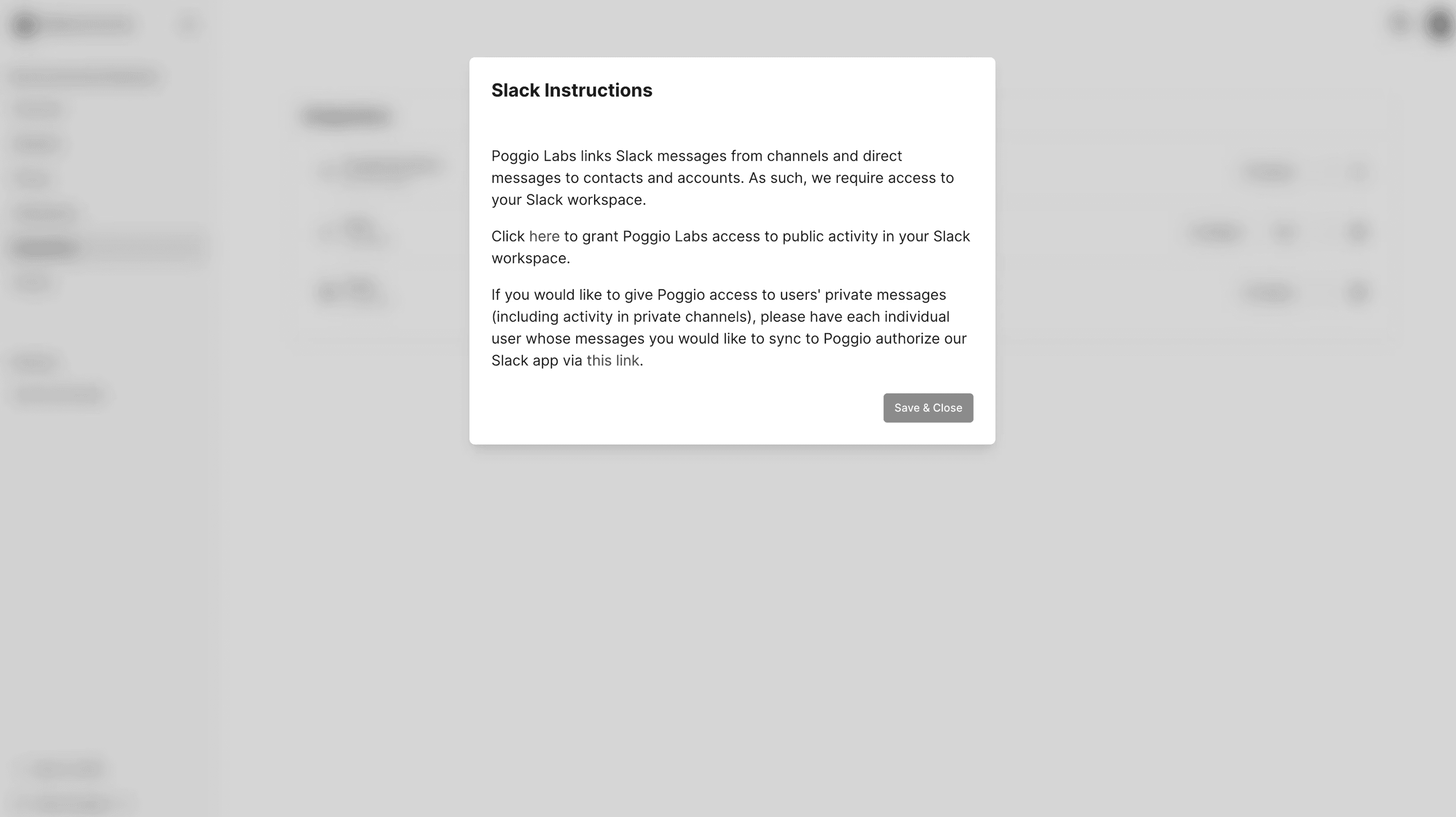
Poggio's initial integration experience was built for a narrow use case, limiting its appeal to our ideal customers and increasing our onboarding overhead. The goal was to enable users to setup integrations independently so they high-quality data tailored to their unique sales motions. Research indicated that users felt the lack of configuration prevented them from leveraging relevant data and hindered their ability to make decisions. This resulted in low trust and poor adoption.
In 1.5 months, we streamlined the setup flow, introduced configurable data sync, and built a framework for future integrations. As a result, 50% of alpha users successfully self-served the the Slack integration and the Google Workspace integration is optimized for the majority, maximizing the value of data.
Contributions
End-to-end design
Scope alignment
Design system
Hybrid team
CTO (acting Product Manager)
Tech lead
Engineer
The extent to which users can configure their integrations prior to the redesign.
Investing in a customer data pipeline
Acquiring more customers by giving users more data
Customers weren't able to leverage their customer data effectively to drive sales motions as the information was rudimentary and hard to consume. Improving data visibility and structure would support Poggio's goal to increase customer acquisition and retention.
To address this, we invested in a pipeline that transformed the way data is shown in the product and created a framework for future data sources. Users can now access 8 categories (~40+ types) of data across the core product areas (accounts, contacts and opportunities), empowering them to make informed decisions and accelerate sales processes.
Contributions
Hybrid team
Front-end engineer
A systems approach to investing in a data pipeline
Categorizing data to scale
Despite a fuzzy Ideal Customer Profile (ICP), I defined data categories commonly used by SMBs and Enterprises. This enabled our team to seamlessly integrate new data into the product.


Defining the quality of data
The type of interactions users have with customers is crucial, but it's the quality that drives organizations' sales strategies. Each data point answers the who, what, when, and where to showcase this interaction quality.
Structuring the data
While data is shared between objects, not all objects are on the same hierarchy. Differentiation is created for the same types of data.

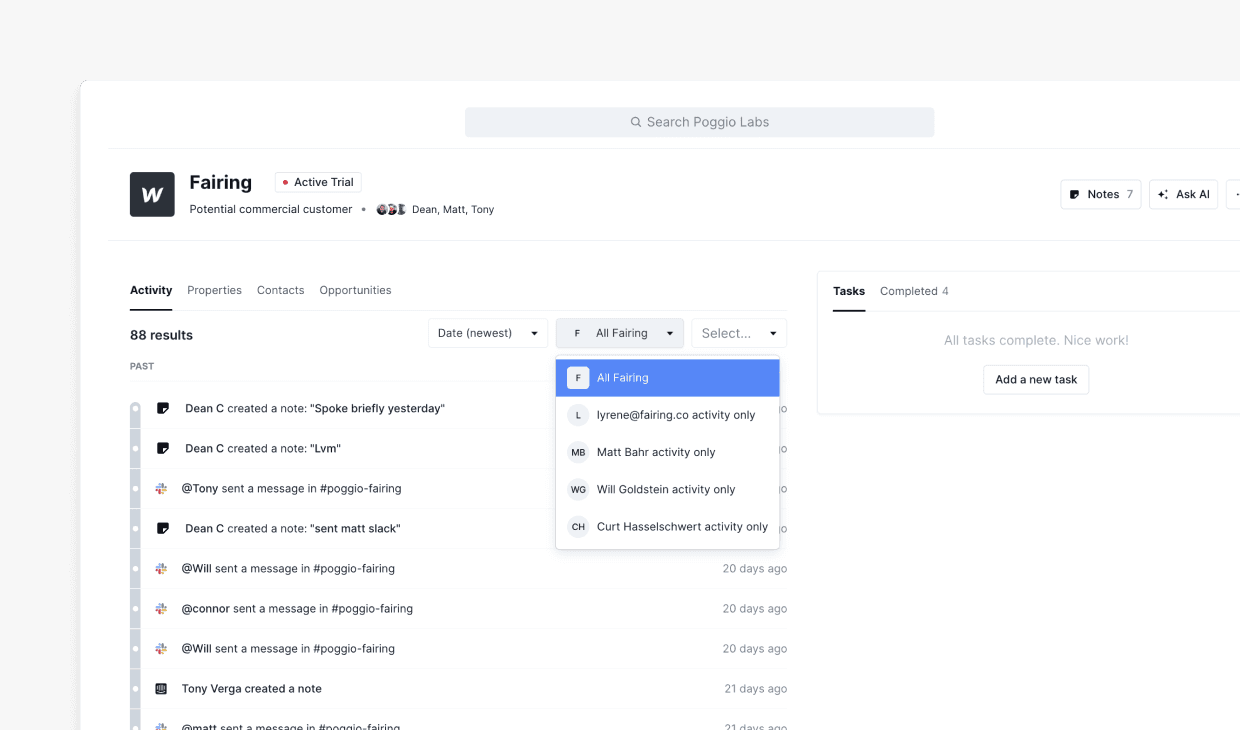
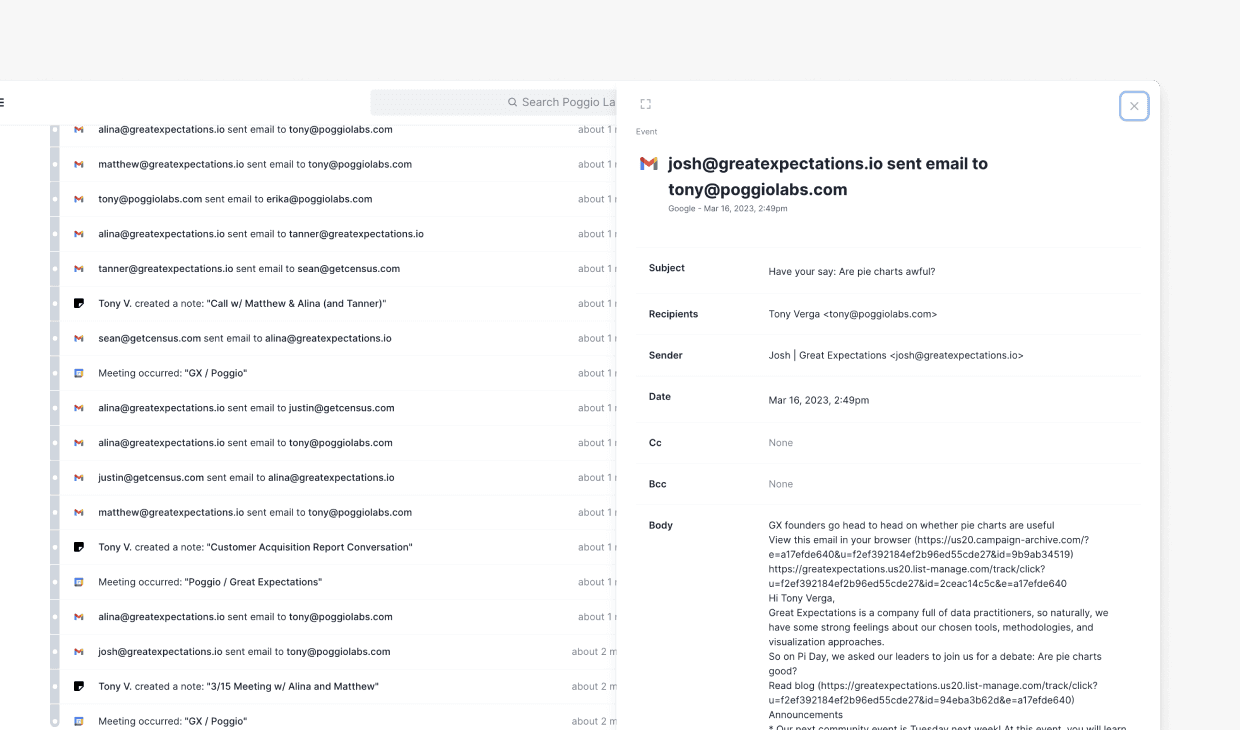
The activity feed and its expanded state in the context of an account when I inherited it.